-
Making the rules part of the domain
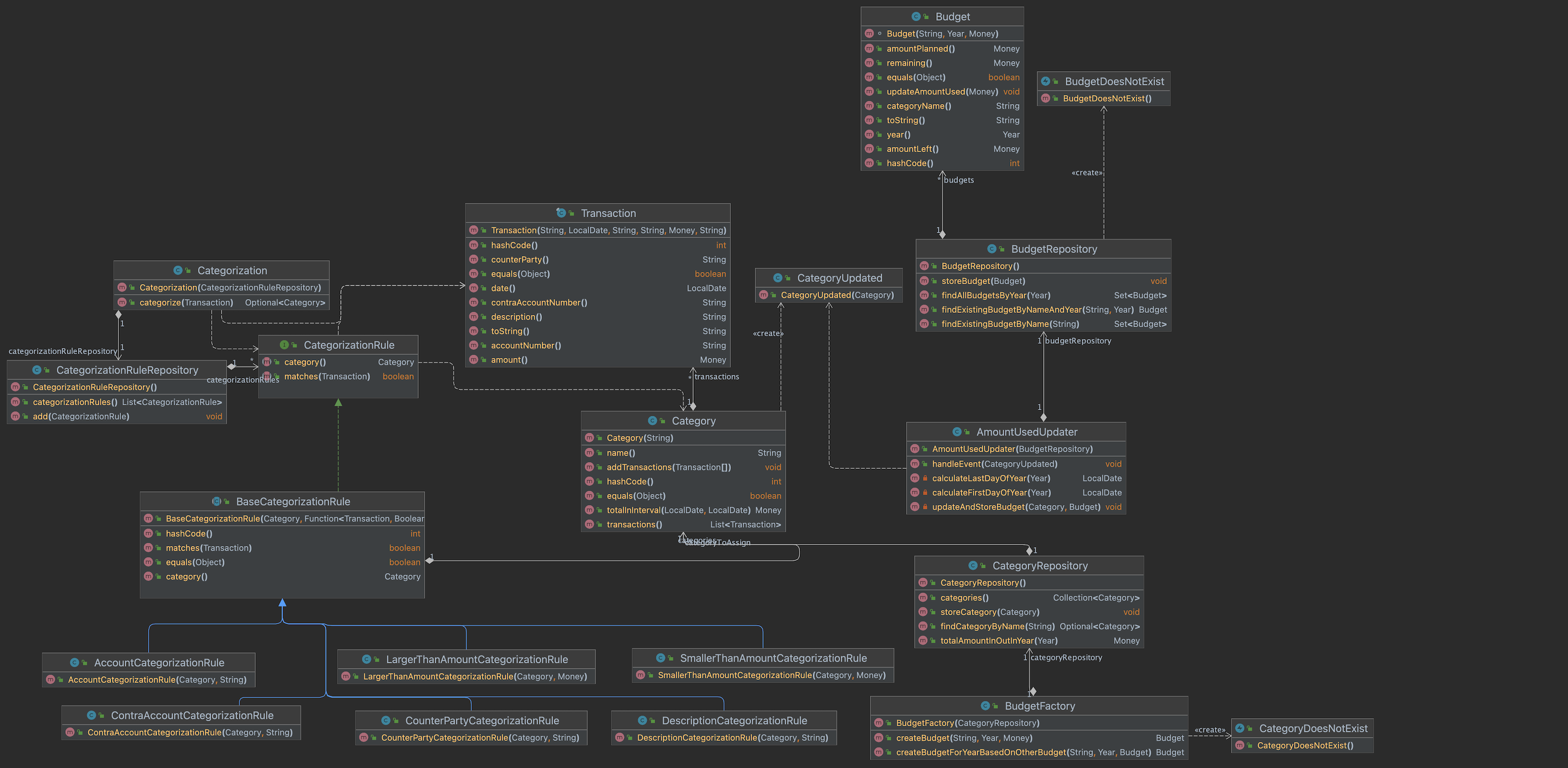
In this blogpost I find a way to make the rules part of the domain. Next to that I develop some code so I can store them on disk. Find the resulting code at GitHub.
-
Not getting financial insight
TL;DR In this post I describe how I discover some imperfections in the current domain. This hampers me in getting financial insight. I fix these imperfections by creating new Category rules. After creating new rules I refactor the rules in to a simpler form. Furthermore I fix Transaction in the domain. As the found issues…
-
Putting the domain to work
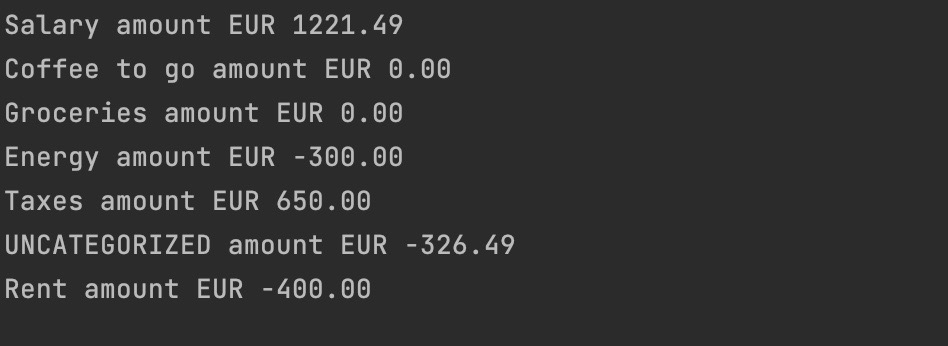
In this post I create a way to import transactions and categorize them. Basically putting the earlier created domain to work. In the end I get some insight into my spendings, however not completely done yet. The resulting code can be found at GitHub.
-
Continuing Domain Driven Design
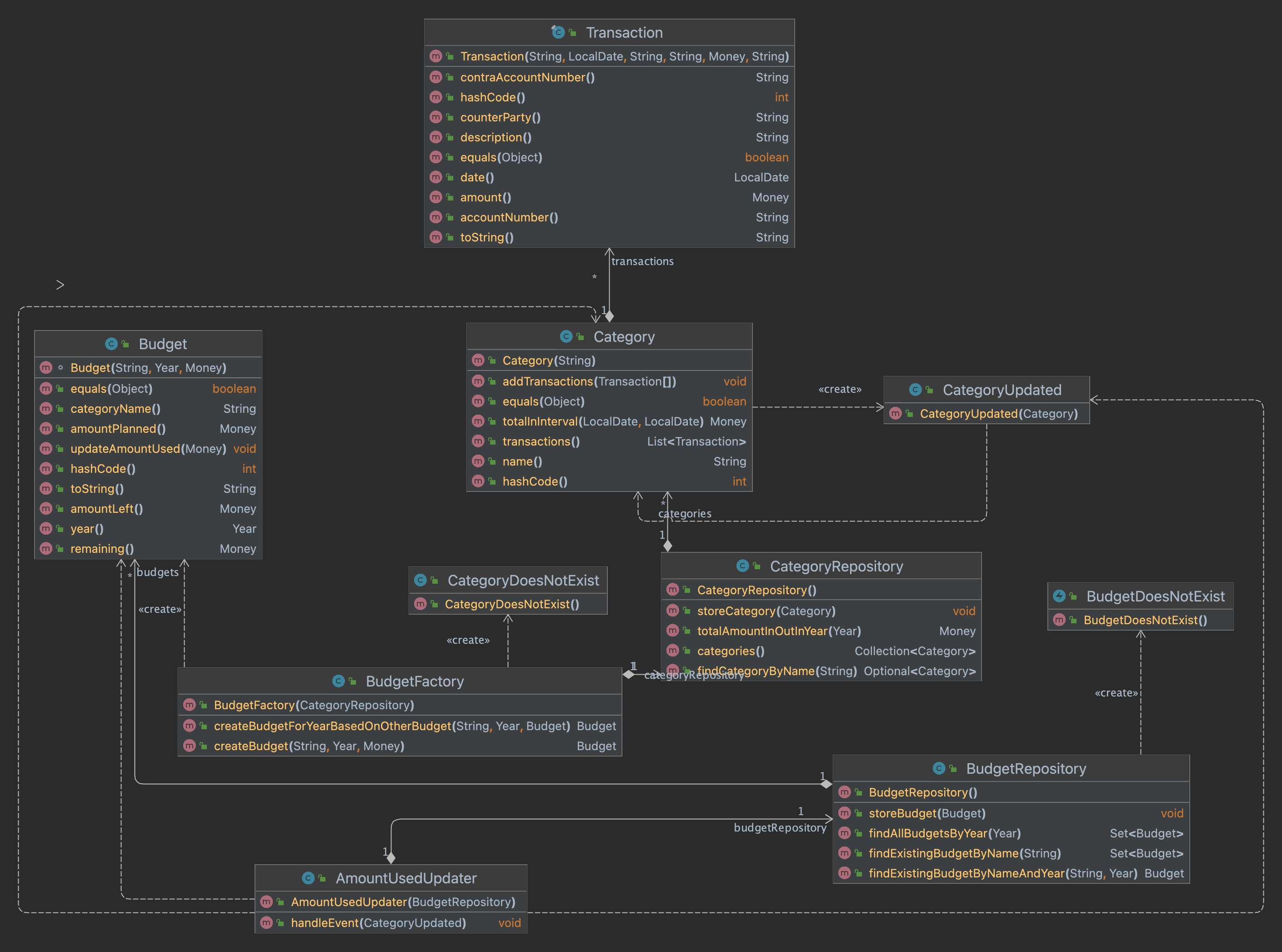
tl;dr In this post I continue my progress towards an DDD version of my favorite pet project. In this iteration I add a way to check the budget against the real expenses. The code is on GitHub and the picture contains the new model. Continuing Domain-Driven Design In my previous blog post I started to…
-
Applying Domain-Driven Design
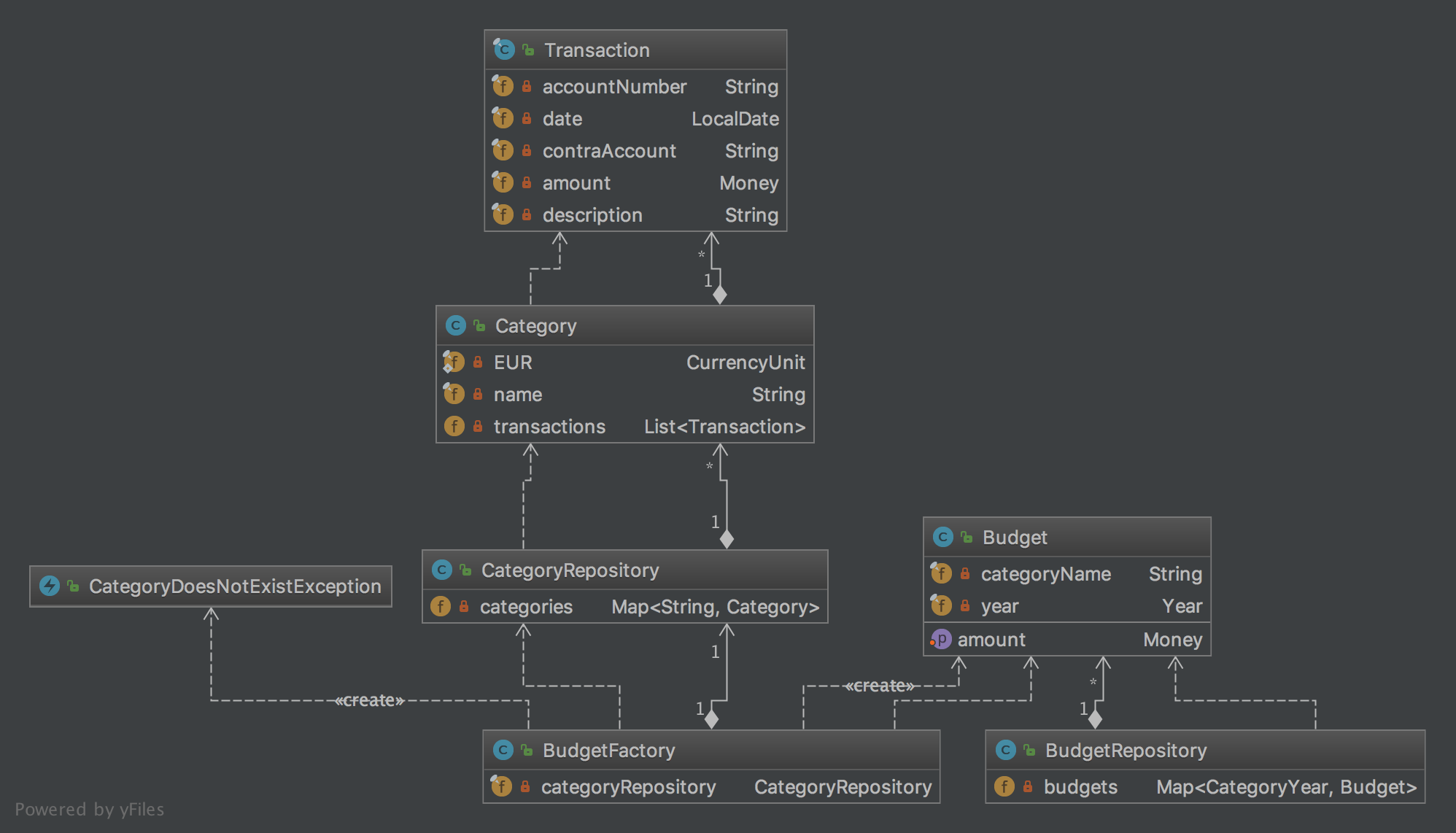
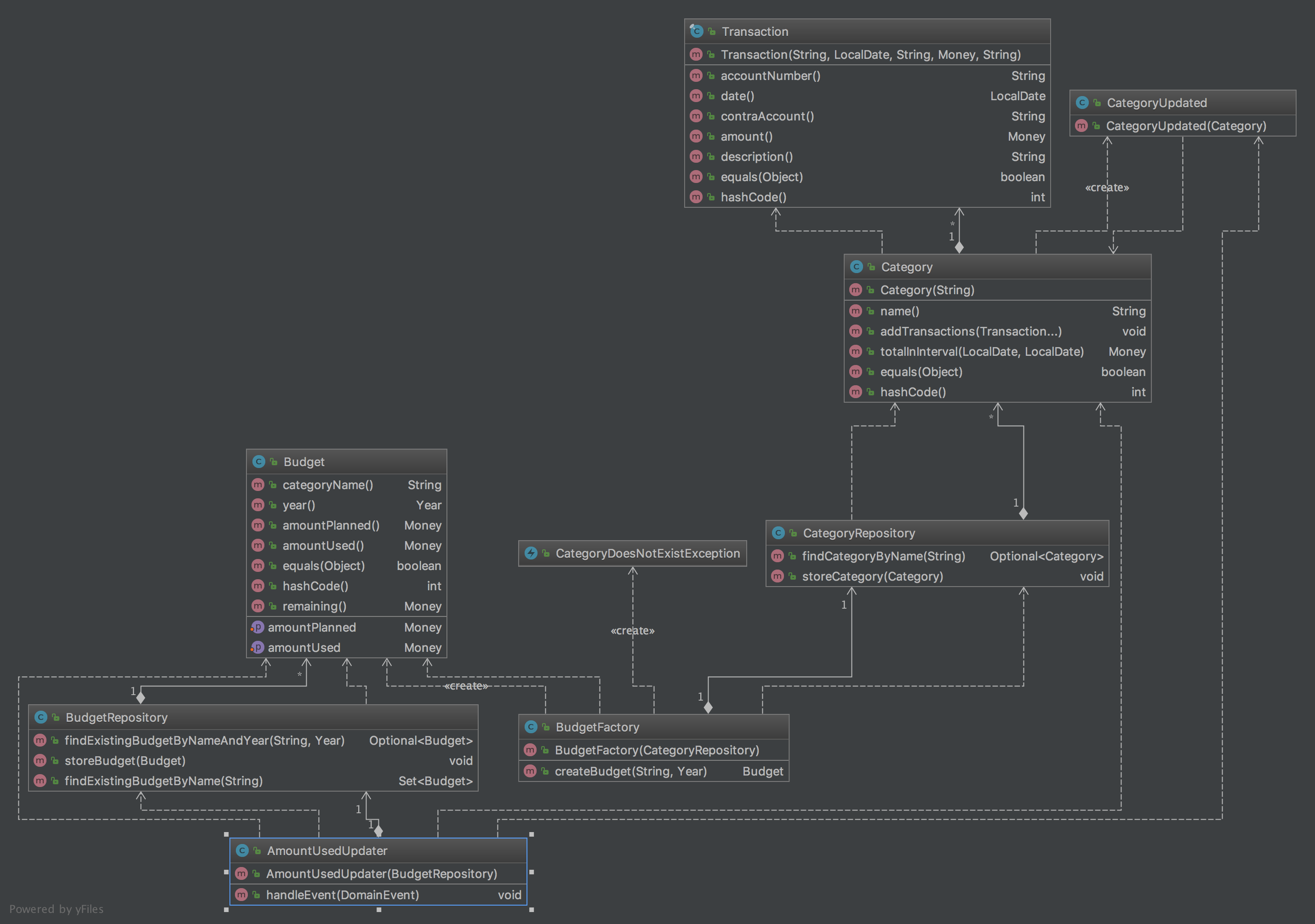
tl;dr In this post I apply Domain-Driven Design to my favorite pet project. The picture above contains the resulting model. The resulting code can be found at GitHub. My attempt on Domain-Driven design As mentioned in my previous post I need to learn Domain-Driven Design for my new job. In this post I apply the…
