-
Categorizing Transactions with Machine Learning and rules

In this post, I’ll demonstrate how combining rules-based systems with machine learning — specifically Random Forest — can significantly improve transaction categorization, particularly for incidental and non-recurring cases. This hybrid approach not only reduces manual efforts but also improves accuracy, helping me make better financial decisions with minimal intervention.
-
Not getting financial insight
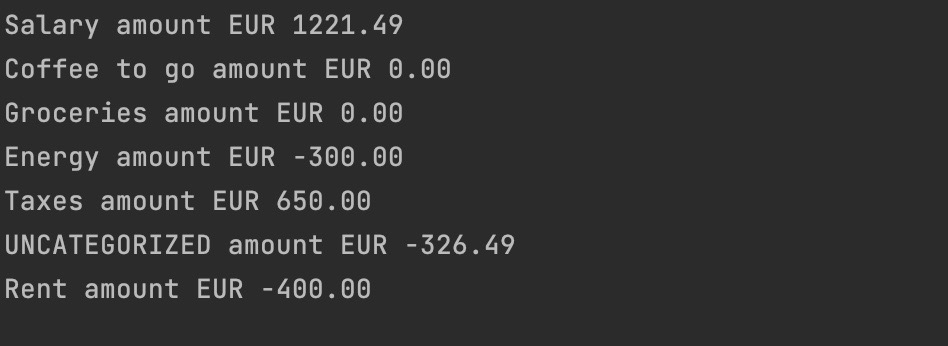
TL;DR In this post I describe how I discover some imperfections in the current domain. This hampers me in getting financial insight. I fix these imperfections by creating new Category rules. After creating new rules I refactor the rules in to a simpler form. Furthermore I fix Transaction in the domain. As the found issues…
-
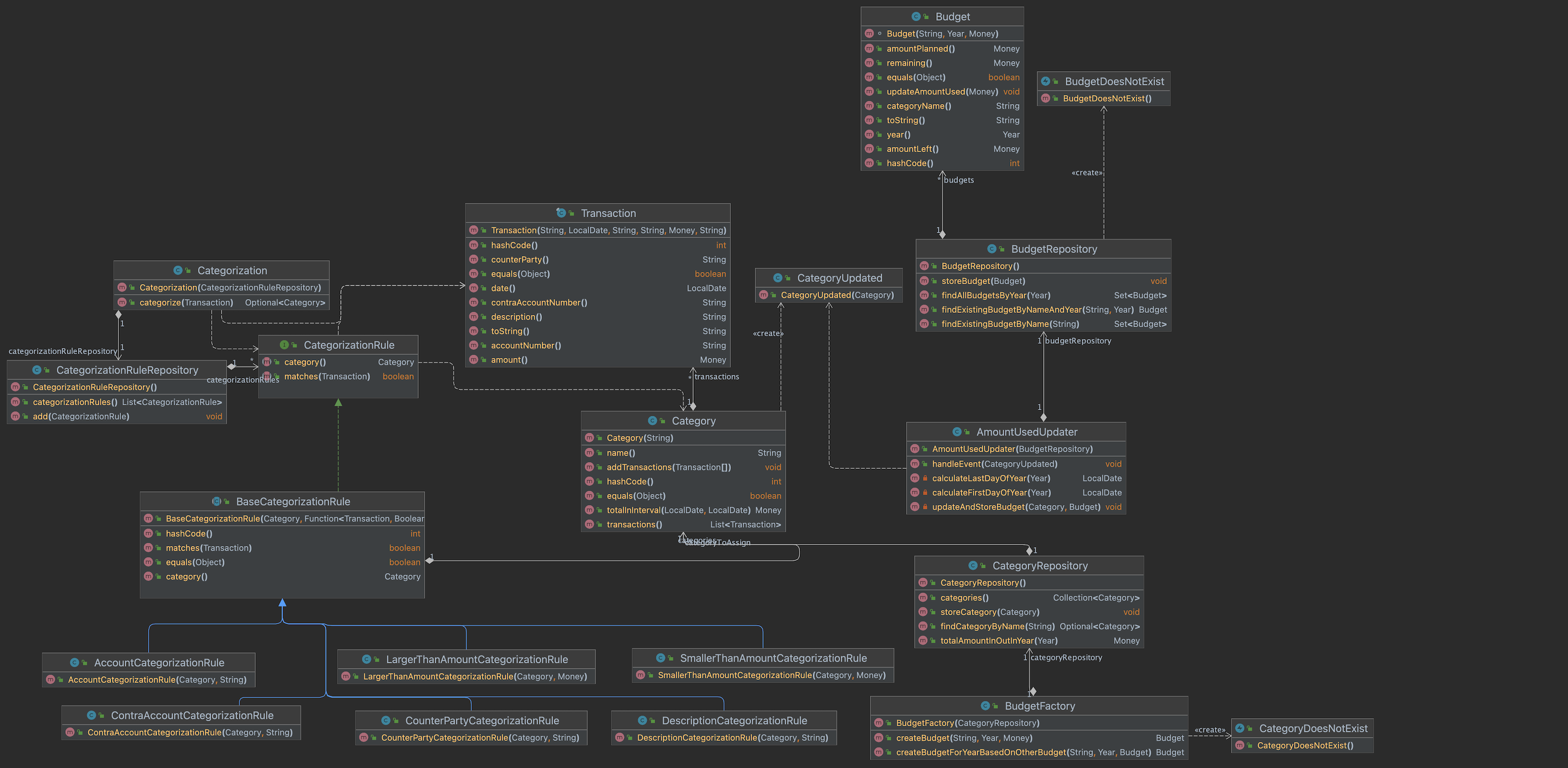
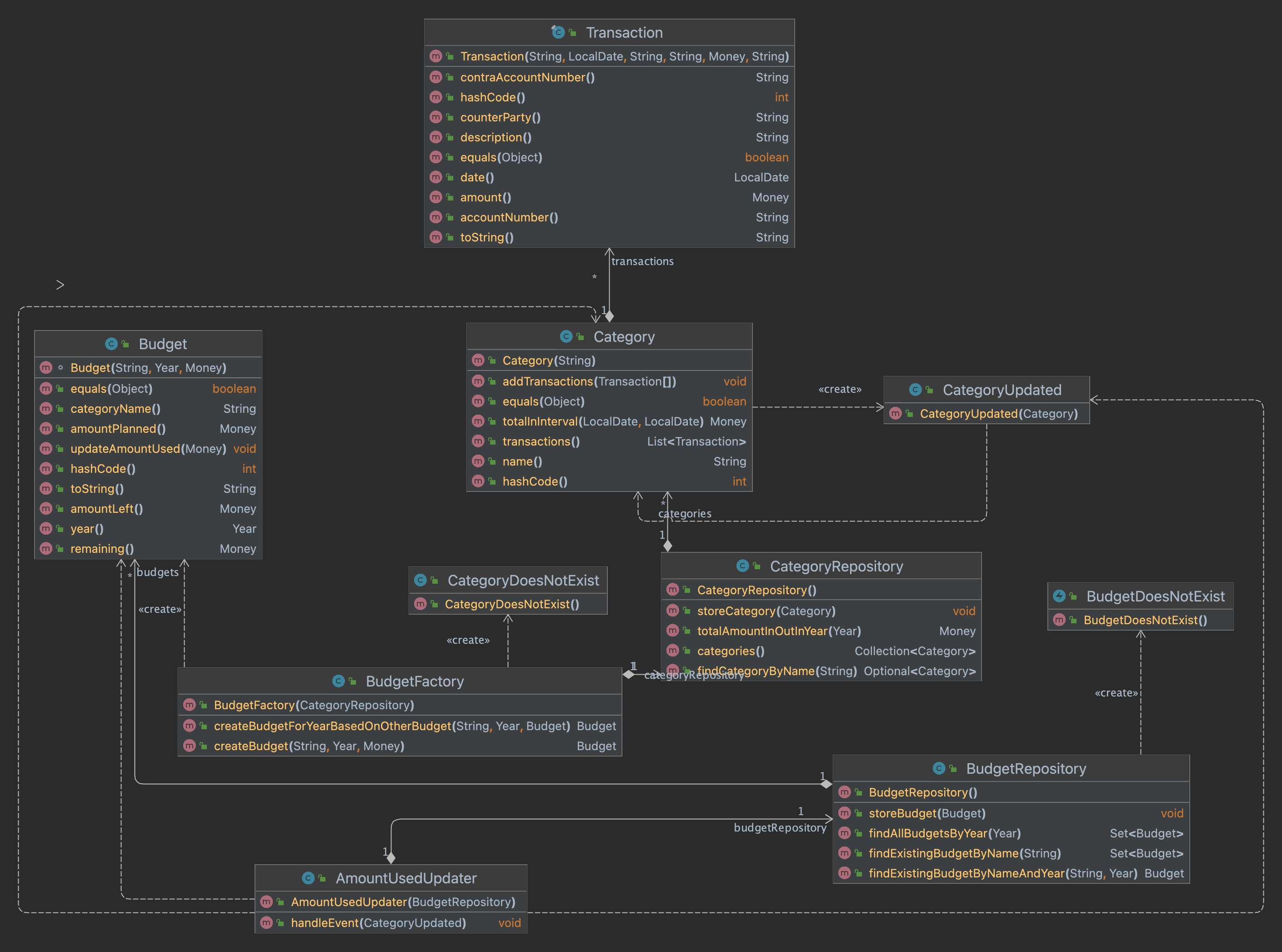
Continuing Domain Driven Design
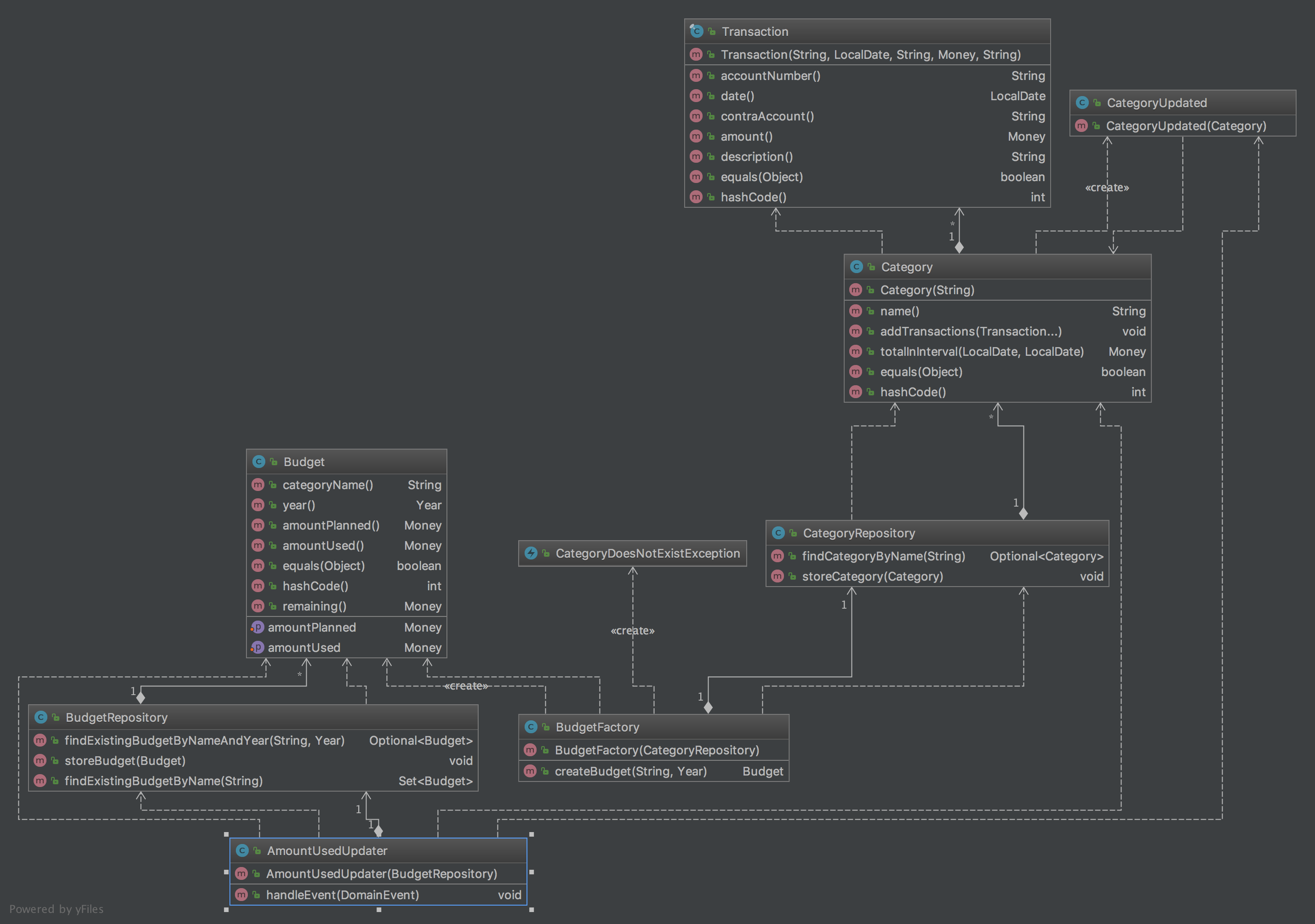
tl;dr In this post I continue my progress towards an DDD version of my favorite pet project. In this iteration I add a way to check the budget against the real expenses. The code is on GitHub and the picture contains the new model. Continuing Domain-Driven Design In my previous blog post I started to…