-
Triple Legacy Migration

TL;DR In this post, I describe tackling a complex triple migration of a large legacy system: upgrading outdated Spring versions, replacing WebSphere with Tomcat, and moving from on-premises servers to a private cloud solution. Despite technical obstacles around transaction management and knowledge gaps, we successfully migrated the million-line codebase while active development continued. The key…
-
AI Pair Programming: Navigating the Hype and Reality

TL;DR In this exploration of AI-powered development, I leveraged Aider with Claude as a pair programming assistant to build a transaction categorizer. Despite the iterative process involving occasional slowdowns and needed refinements, the collaboration yielded surprisingly robust results. By containerizing Aider and integrating the Anthropic API, I developed a sophisticated tool with capabilities that would…
-
Categorizing Transactions with Machine Learning and rules

In this post, I’ll demonstrate how combining rules-based systems with machine learning — specifically Random Forest — can significantly improve transaction categorization, particularly for incidental and non-recurring cases. This hybrid approach not only reduces manual efforts but also improves accuracy, helping me make better financial decisions with minimal intervention.
-
Making the rules part of the domain
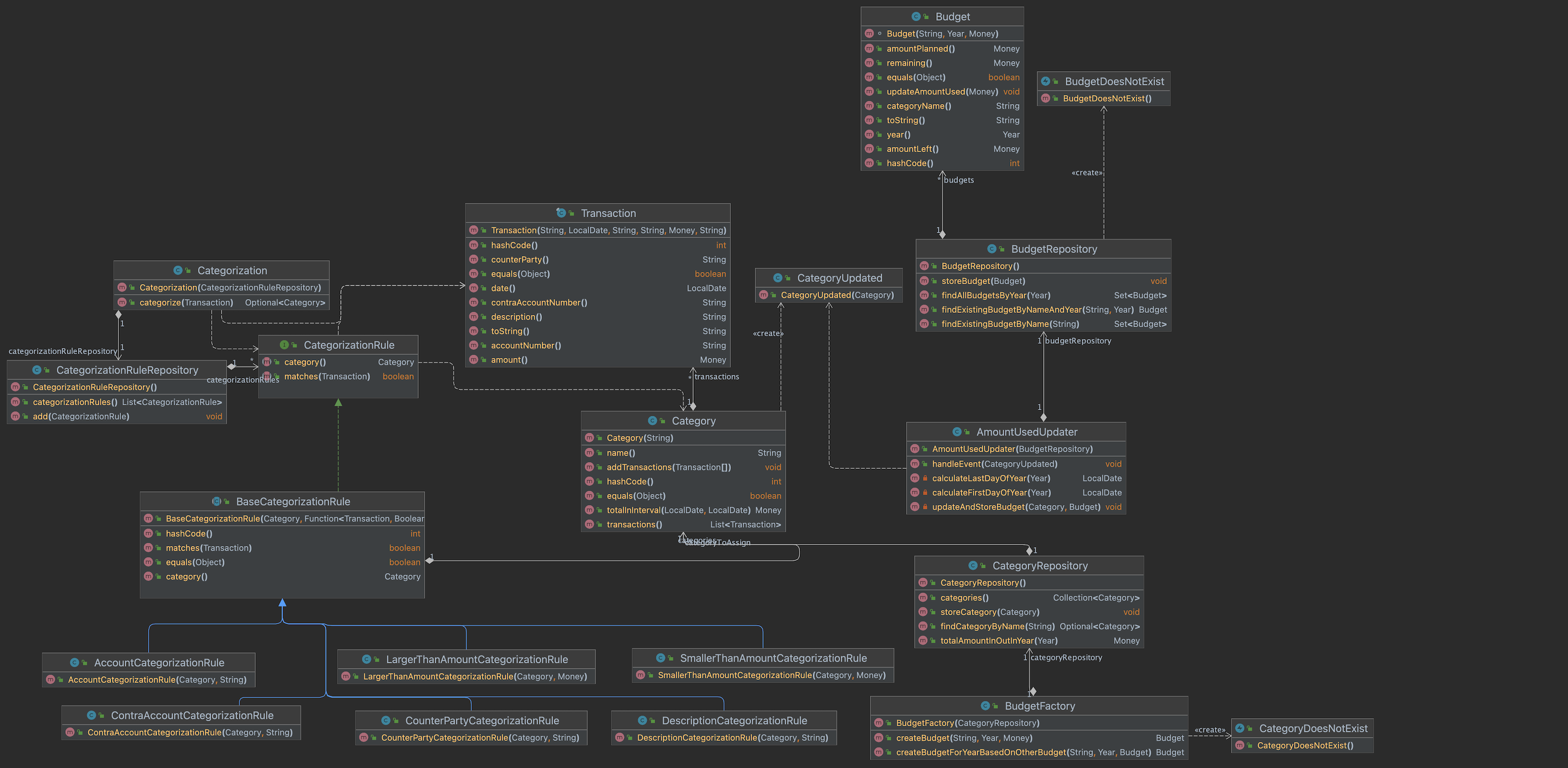
In this blogpost I find a way to make the rules part of the domain. Next to that I develop some code so I can store them on disk. Find the resulting code at GitHub.
-
Not getting financial insight
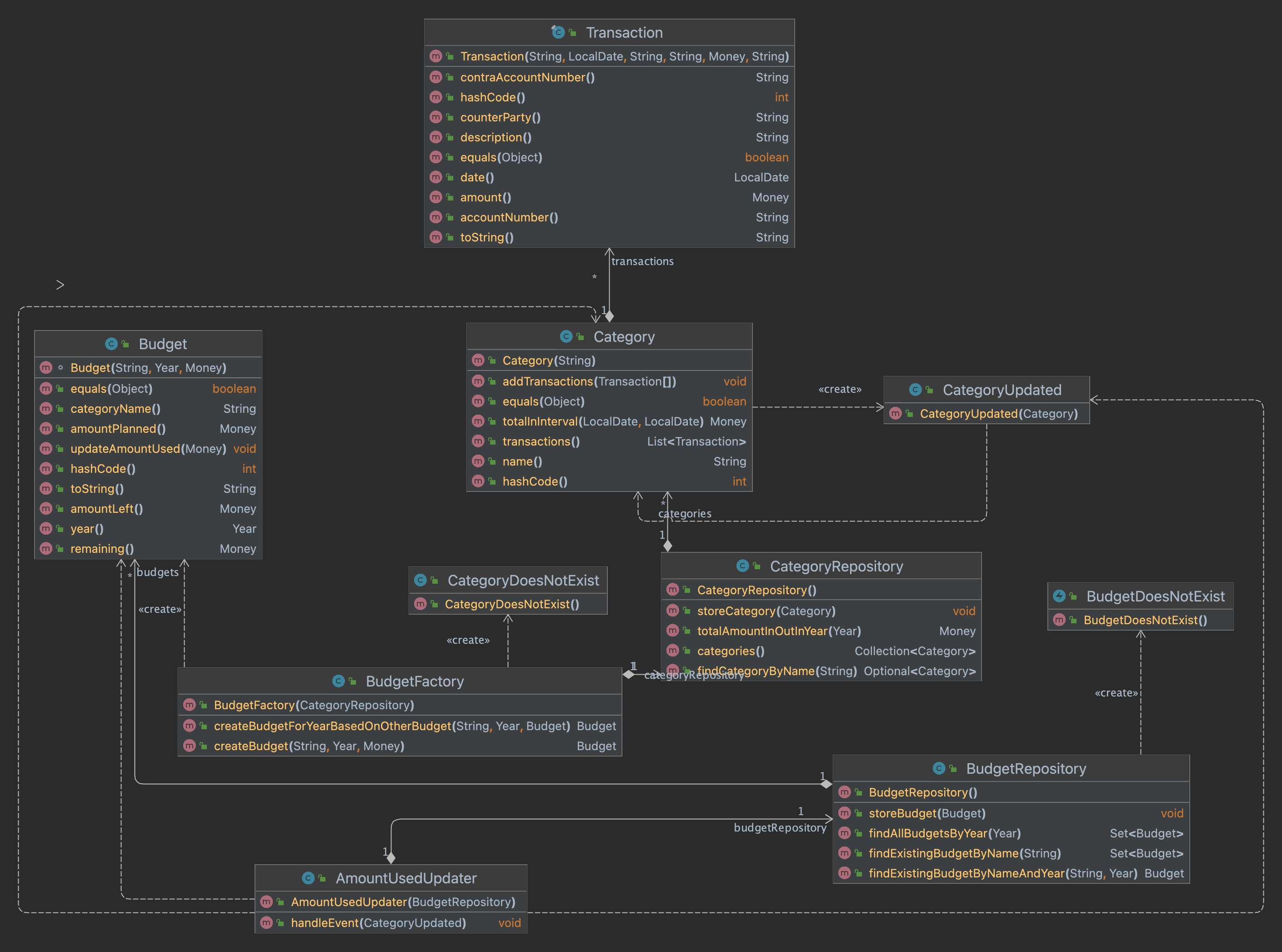
TL;DR In this post I describe how I discover some imperfections in the current domain. This hampers me in getting financial insight. I fix these imperfections by creating new Category rules. After creating new rules I refactor the rules in to a simpler form. Furthermore I fix Transaction in the domain. As the found issues…
