-
Teaching the App to Categorize Transactions
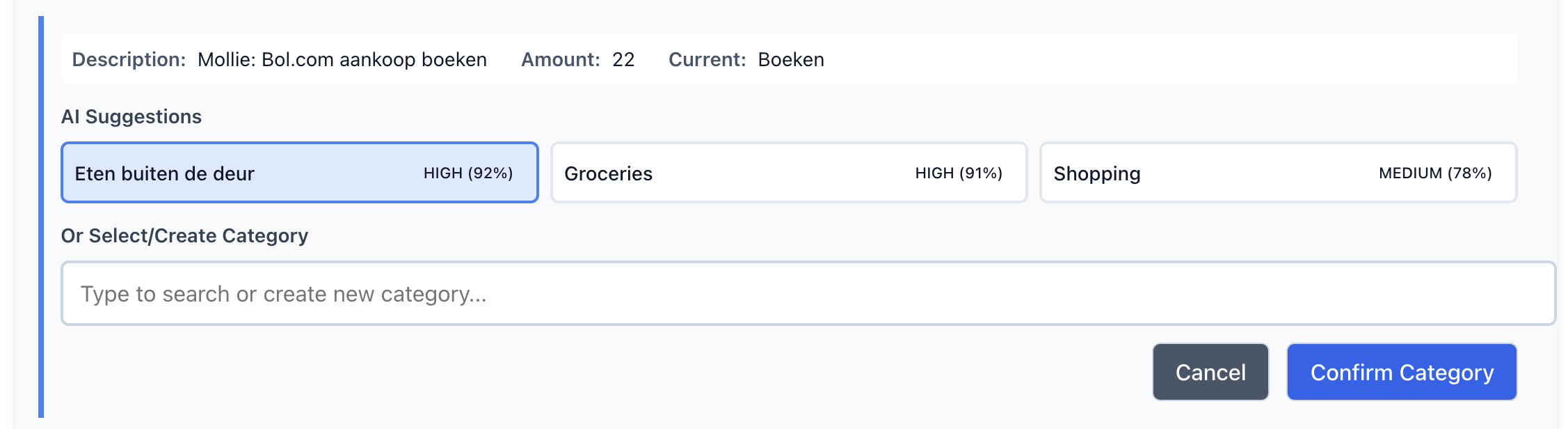
The whole reason I built this tool is that I was tired of writing categorization rules that broke every time my bank reformatted a description. This post covers how I replaced that with a vector similarity search using transformer embeddings, where the system learns from what you’ve already categorized rather than from rules you have to maintain. The approach…
-
Building My Own Personal Finance App From Scratch (With AI Help)
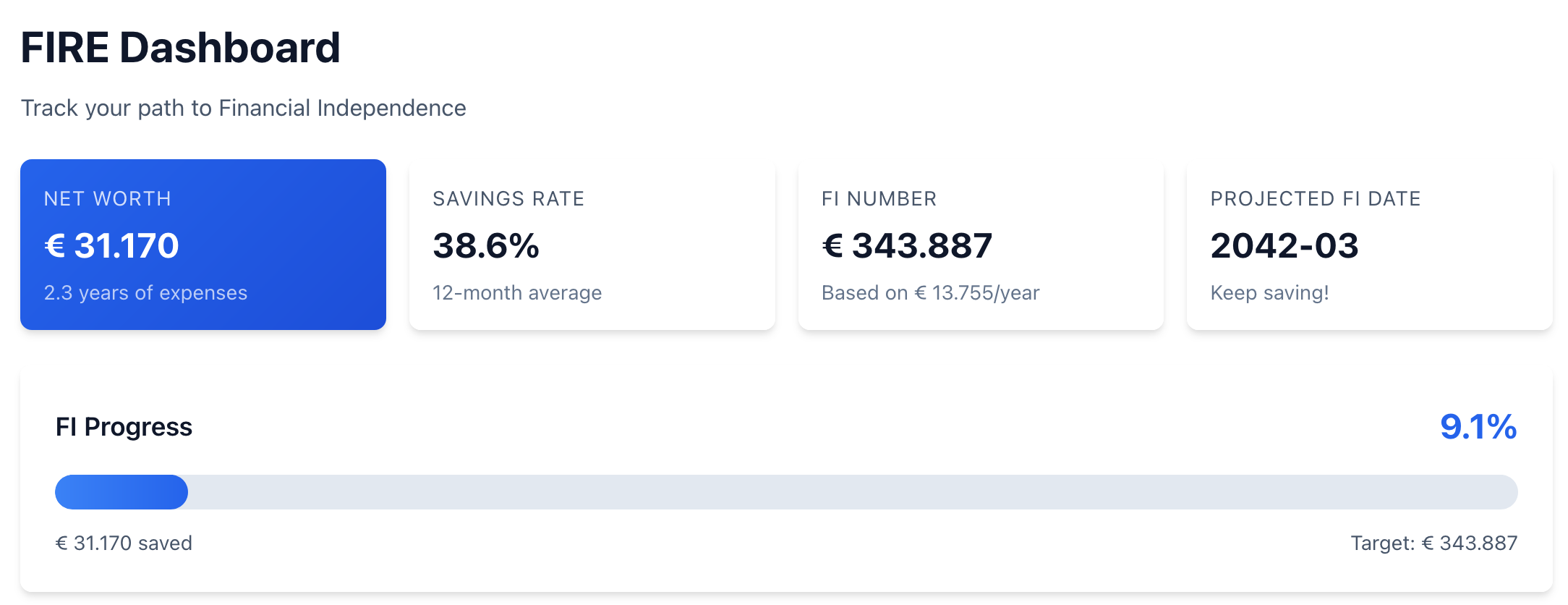
TL;DR: I got tired of manually categorizing transactions in Firefly III and wanted a FIRE dashboard that doesn’t require three clicks to find. So I built my own finance tool from scratch, using Claude Code as my primary development method. This series documents what happened, the things that worked surprisingly well, and the things that went sideways. The Moment It Started…
-
Categorizing Transactions with Machine Learning and rules

In this post, I’ll demonstrate how combining rules-based systems with machine learning — specifically Random Forest — can significantly improve transaction categorization, particularly for incidental and non-recurring cases. This hybrid approach not only reduces manual efforts but also improves accuracy, helping me make better financial decisions with minimal intervention.
-
Making the rules part of the domain
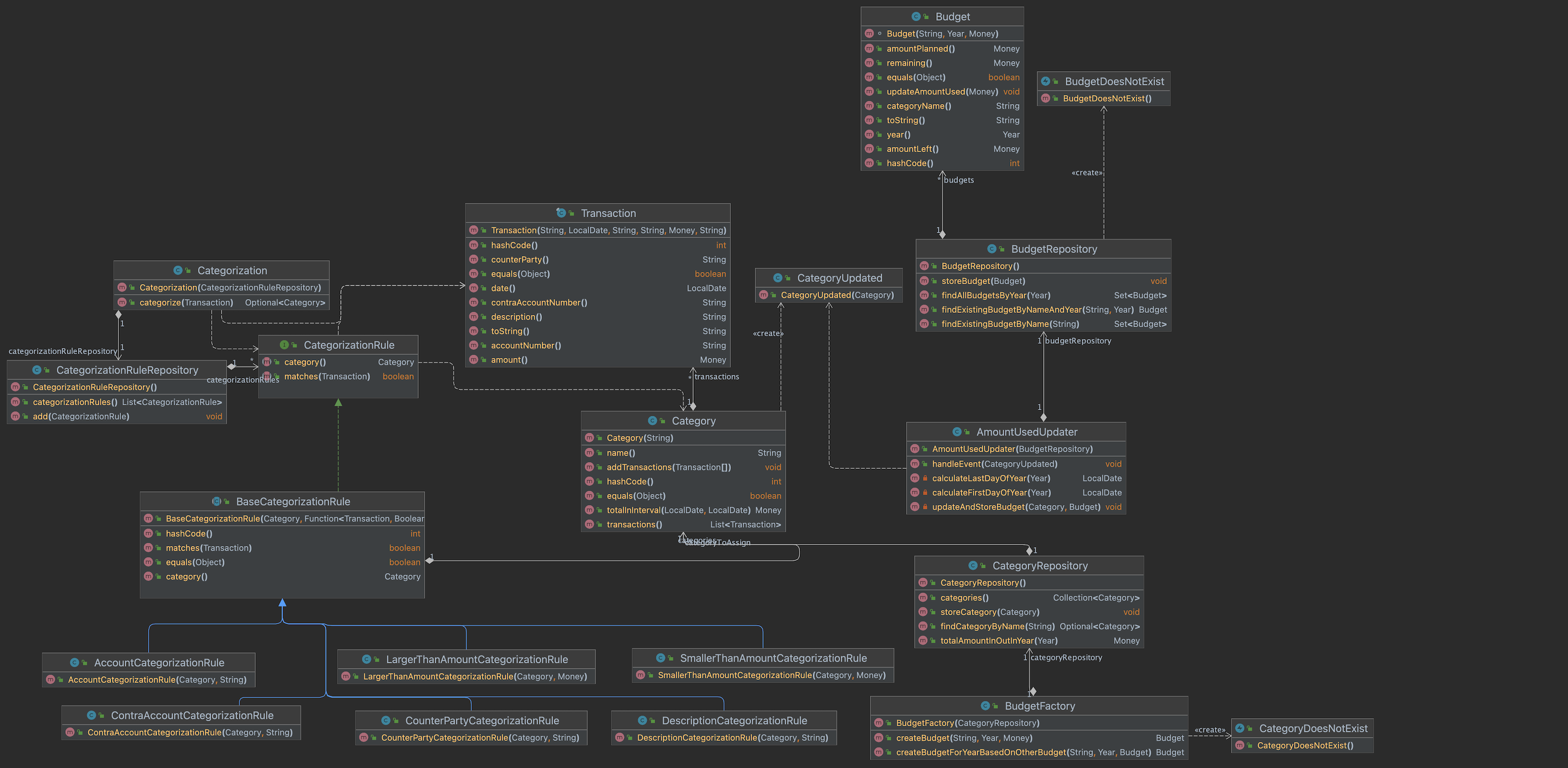
-
Not getting financial insight
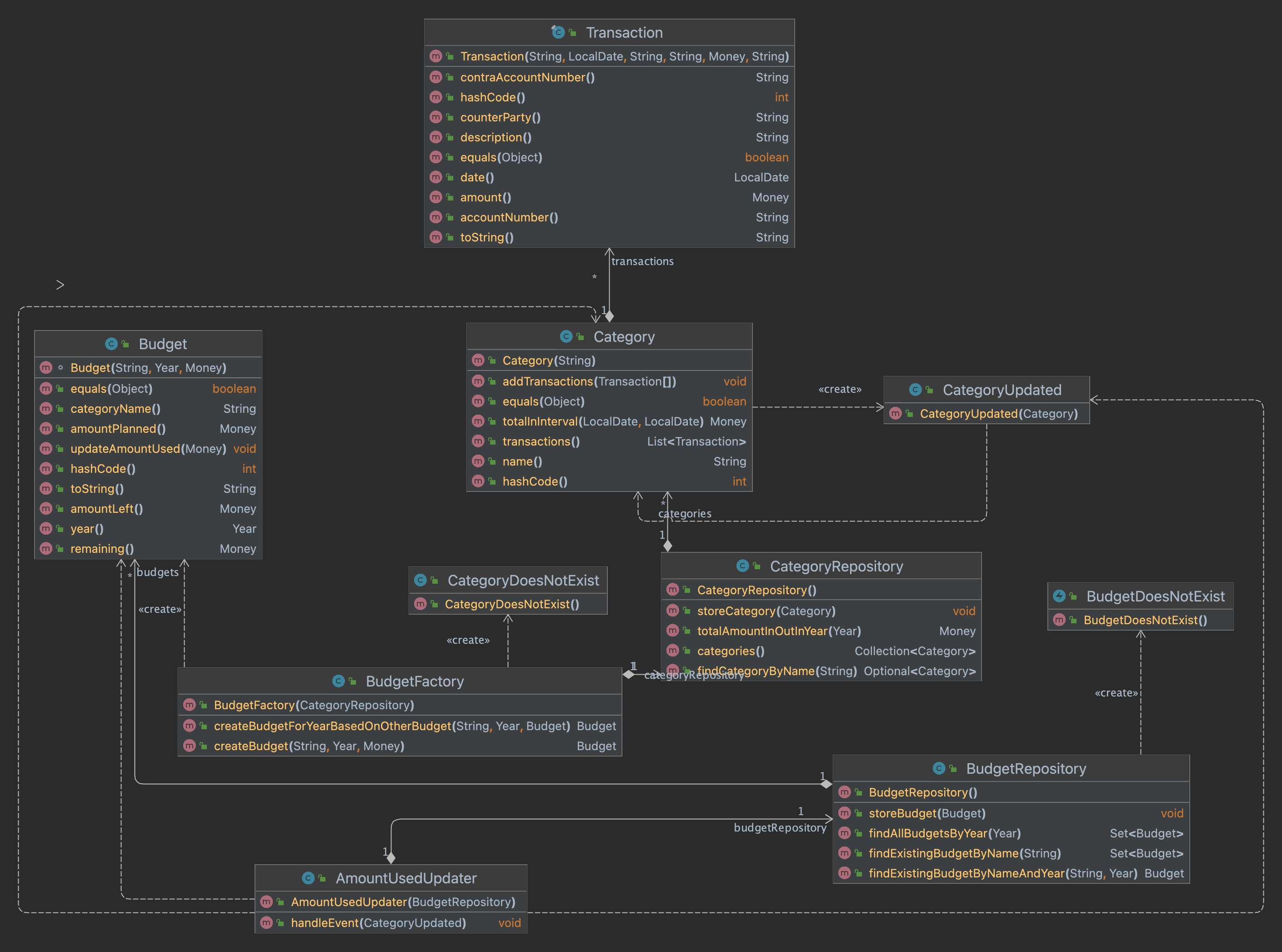
TL;DR In this post I describe how I discover some imperfections in the current domain. This hampers me in getting financial insight. I fix these imperfections by creating new Category rules. After creating new rules I refactor the rules in to a simpler form. Furthermore I fix Transaction in the domain. As the found issues…