TL;DR: The whole reason I built this tool is that I was tired of writing categorization rules that broke every time my bank reformatted a description. This post covers how I replaced that with a vector similarity search using transformer embeddings, where the system learns from what you’ve already categorized rather than from rules you have to maintain. The approach runs completely offline and uses a weighted embedding model to handle payment processors like Mollie.
I mentioned in the first post that the categorization was one of the things that worked surprisingly well on the first attempt. That was true, but it wasn’t the full story. The first attempt got the architecture right and the basic mechanics working. Then I spent another few sessions chasing edge cases that I hadn’t thought about until real transactions started flowing through it.
Here is what I actually built, and how it evolved.
The basic idea
The categorization system stores embeddings of previously categorized transactions in memory. When a new transaction comes in, it computes an embedding for that transaction and finds the most similar ones already in the index. If the closest match is similar enough, it suggests the same category. If nothing in the index is similar enough, it falls back to “most common category for this transaction type”, which at least gives you something to work with.
No training phase. No labeled dataset required. Categorize a dozen transactions manually, and the system starts picking up the patterns.

The embedding model is all-MiniLM-L6-v2, which Spring AI downloads from HuggingFace the first time you run the application and then caches locally. It’s about 80MB. No API calls, no external dependencies after that first download.
The implementation in TransformerEmbeddingAdapter
The part I found most interesting was deciding what to actually embed. My first instinct was to concatenate everything into one string and throw it at the model. That works, but it means all features get equal weight, and some features matter a lot more than others.
Instead, TransformerEmbeddingAdapter computes separate embeddings for four features: the transaction description, the counterparty (name plus IBAN), the amount, and the source account. Then JVectorSearchAdapter combines them with configurable weights before doing the similarity search.
ublic FeatureEmbeddings computeFeatureEmbeddings(Transaction transaction) {
String description = buildDescriptionText(transaction);
String counterparty = buildCounterpartyText(transaction);
String amount = buildAmountText(transaction);
String sourceAccount = buildSourceAccountText(transaction);
return new FeatureEmbeddings(
embedText(description),
embedText(counterparty),
embedText(amount),
embedText(sourceAccount)
);
}The counterparty text combines name and IBAN: "Starbucks NL12ABNA0123456789". The source account encodes account role and name: "CREDIT_CARD:MyAmex". Both of these carry more categorization signal than the free-text description, which can vary wildly for the same merchant.
The default weights in application.yml reflect that: counterparty gets 0.50, amount gets 0.20, description gets 0.15, source account gets 0.15. Those numbers are configurable. I tuned them by hand against a batch of real transactions until the obvious cases stopped being wrong.
The Mollie problem
This is the edge case that made me glad I went with embeddings rather than exact IBAN matching.
My first instinct was to add an exact IBAN lookup before the similarity search. If you’ve bought groceries from Albert Heijn twenty times and they always come through on the same IBAN, that’s a strong signal. Why not just use it directly?
The problem is payment processors. Mollie, Stripe, and PayPal all aggregate payments for thousands of different merchants through the same IBAN. So you might have:
- “Coolblue order #12345” through
NL91ABNA0417164300(Mollie) categorized as Electronics - “Bol.com order #67890” through
NL91ABNA0417164300(Mollie) a week later
Exact IBAN matching would suggest Electronics for the Bol.com transaction. Wrong.
Embedding the IBAN as part of the counterparty text sidesteps this cleanly. The transformer sees “Coolblue NL91ABNA0417164300” and “Bol.com NL91ABNA0417164300” as similar in some ways (same payment channel) but different enough in others (different merchant name, different description) that the similarity score reflects the actual situation. The IBAN is one signal among many rather than a deterministic lookup key.
For direct merchants where the name and IBAN are always the same, the match scores are very high. For payment processors, the description ends up doing most of the work, which is what you want.
The similarity search in JVectorSearchAdapter
The search is brute-force K-nearest-neighbors. Every categorized transaction gets a weighted embedding stored in a map (keyed by transaction ID). When you ask for suggestions, the adapter computes cosine similarity against every stored vector and returns the top k results.
for (Map.Entry<Long, float[]> entry : vectorMap.entrySet()) {
double similarity = embeddingPort.cosineSimilarity(queryEmbedding, entry.getValue());
if (amountMatchingEnabled) {
double amountBoost = computeAmountBoost(
transaction.getAmount(),
transactionMap.get(entry.getKey()).getAmount()
);
similarity = Math.min(1.0, similarity + amountBoost);
}
if (similarity >= minimumSimilarityThreshold) {
scores.add(new SimilarityScore(entry.getKey(), similarity));
}
}The amount boost is a small bonus for transactions where the amounts match exactly or nearly match. It helps with subscriptions, where the description and counterparty are identical every month and you mostly want to confirm that the amount being the same strengthens the match.
Brute-force is fine for personal finance. Most people have under 10,000 transactions. Brute-force against 10,000 vectors takes around 50ms with JVector, which uses SIMD acceleration via Java’s Vector API. That’s comfortable for a suggestion on page load. If the index ever grows to 50,000+ transactions, moving to an approximate index would make sense, but that’s a future problem.
Ambiguity detection in IntelligentCategorizationServiceImpl
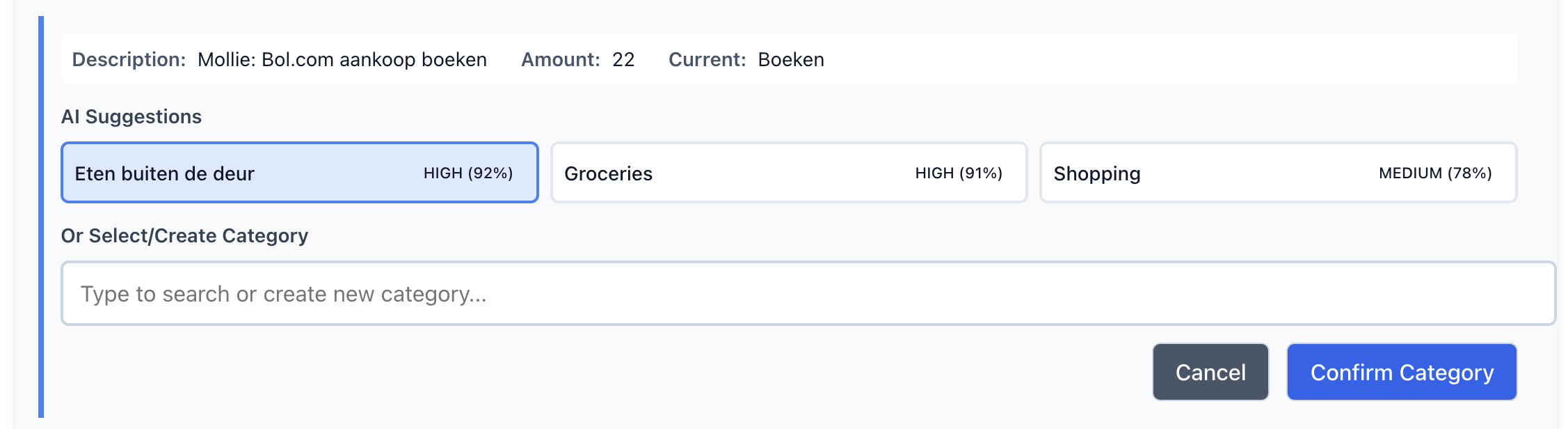
After the first version was working, I noticed a subtle problem. When two categories both scored above the HIGH confidence threshold (0.85), the system would auto-apply the higher one. The margin between them could be tiny. Groceries at 87% and Shopping at 85% looks like a clear winner, but it isn’t really. Both are equally plausible from the model’s perspective.
The fix was to get the top two suggestions and check whether they’re too close together before deciding whether to auto-apply.
if (topSuggestion.confidence() >= CategorizationConfidence.HIGH.getThreshold() &&
secondSuggestion.confidence() >= CategorizationConfidence.HIGH.getThreshold()) {
ambiguous = true;
} else if (topSuggestion.confidence() >= CategorizationConfidence.HIGH.getThreshold() &&
secondSuggestion.confidence() >= 0.80) {
ambiguous = true;
}
if (ambiguous) {
return new CategorySuggestion(
topSuggestion.category(),
0.75, // MEDIUM confidence - requires manual review
topSuggestion.reasoning() + ambiguityNote
);
}When ambiguity is detected, the suggestion gets downgraded to MEDIUM confidence with a note saying which other category was competing. The user sees the top suggestion but has to confirm it rather than having it applied automatically. It’s a small thing but it makes the system feel more honest about what it doesn’t know.
Lessons learned
The weighted feature embedding approach turned out to be more robust than I expected. Putting the IBAN inside the embedding text rather than using it as a lookup key is the kind of non-obvious decision that only becomes obvious after you think through a payment processor scenario. The model doesn’t need explicit instruction about what an IBAN is or what Mollie does. Putting “Coolblue NL91ABNA0417164300” and “Bol.com NL91ABNA0417164300” into the same vector space and asking how similar they are to a query vector gives you the right answer automatically.
The confidence thresholds feel a bit arbitrary, and they probably are. HIGH at 0.85 means “auto-apply”, MEDIUM at 0.60 means “suggest but ask”, LOW means “here’s a guess.” I tuned those against my own transactions. Someone with different spending patterns might need different values. Making them configurable in application.yml was the right call.
The ambiguity detection is the piece I’m most pleased with. It’s a small addition to IntelligentCategorizationServiceImpl, maybe twenty lines, and it meaningfully reduces the number of times the system confidently gets it wrong.
Previously in this series: Building My Own Personal Finance App From Scratch (With AI Help)